- 阅读本手册需要一定mxnet、gluon操作基础
- 本文使用cpu训练代码
- 本文github地址:https://github.com/zmkwjx/GluonTS-Learning-in-Action
- GluonTS官网地址:https://gluon-ts.mxnet.io
1、环境以及安装
1.1 本文开发环境:ubuntu16.04TS、python3.7
1.2 快速安装
1 | pip install matplotlib numpy pandas pathlib |
2、训练程序
1 | #Third-party imports |
2.1 加载训练数据 Twitter_volume_AMZN.csv
1 | url = "./data/Twitter_volume_AMZN.csv" |
pd.read_csv 将csv文件读入并转化为数据框形式
common.ListDataset 加载训练数据
2.2 解读 ListDataset
class gluonts.dataset.common.ListDataset(data_iter: Iterable[Dict[str, Any]], freq: str, one_dim_target: bool = True)
data_iter: 可迭代对象产生数据集中的所有项目。每个项目都应该是一个将字符串映射到值的字典。例如:{“start”: “2014-09-07”, “target”: [0.1, 0.2]}
freq: 时间序列中的观察频率。
one_dim_target: 是否仅接受单变量目标时间序列。
2.3 训练现有模型
GluonTS带有许多预先构建的模型。用户所需要做的就是配置一些超参数。现有模型专注于(但不限于)概率预测。概率预测是以概率分布的形式进行的预测,而不是简单的单点估计。
1 | estimator = deepar.DeepAREstimator(freq="H", prediction_length=24) |
构造一个DeepAR网络、并进行训练
prediction_length: 需要预测的时间长度
training_data: 训练数据
2.4 预览训练结果
1 | for test_entry, forecast in zip(train_data, predictor.predict(train_data)): |
预测结果
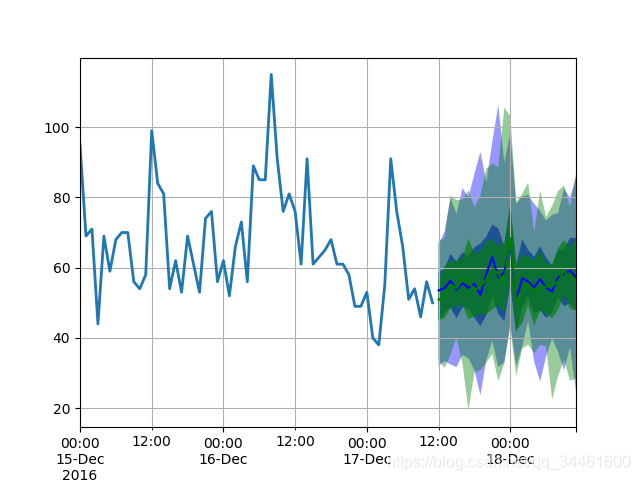
2.5 输出训练结果
1 | prediction = next(predictor.predict(train_data)) |
OUT
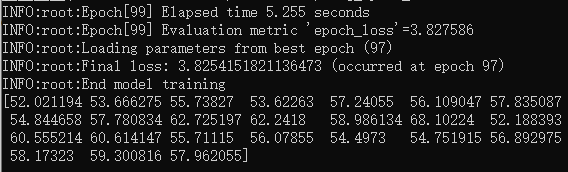
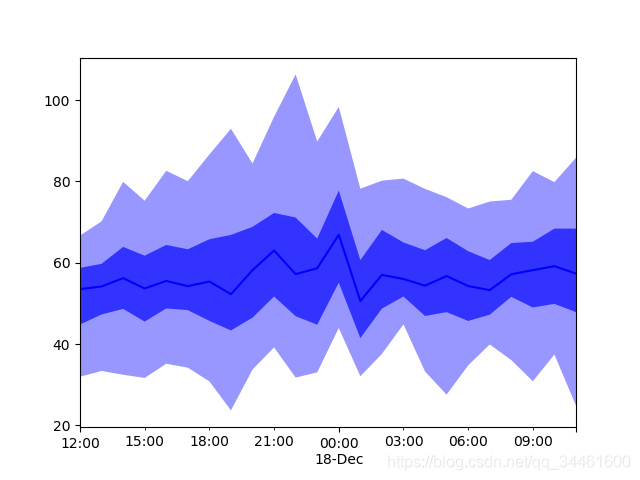
2.5 保存训练模型
1 | predictor.serialize(Path("此处填入Model文件夹的绝对路径")) |
2.6 使用训练模型
1 | predictor = Predictor.deserialize(Path("此处填入Model文件夹的绝对路径")) |
- 例子
1 | import pandas as pd |